データ個数が2倍ずつになっているので、両対数グラフにしました。
CUDA SDK sampleをいじってみる その1 Reduction編
作成日 2008/6/4 最終更新日 2008/6/4
まずは、SDKについているサンプルをいろいろといじるところからはじめてみようと思います。
この記事を読む場合は、サンプルのソースコードが手元にあることが前提になっているので、
詳細を確認したい方はまずそちらの入手をお願いします。
1.Reductionとは
ReductionあるいはDimensional Reductionとは、次元削減などと呼ばれる計算です。
これは配列の次数を減らす作業で、大量のデータからその特徴となる指標を取り出します。
統計を取るということは、計算としては次元削減ですので、統計計算にGPGPUを用いようとする今回の実験の目的からいって、
この次元削減が非常に重要なテクニックとなります。
たとえば、合計・平均値・中央値・分散などは次元削減の1種ですし、
加重平均・共分散などは、2つの配列を用いて計算される次元削減です。
さて、並列プログラムによって高速化できるReductionはどのようなものでしょうか。
普通に全部合計をとるとしましょう。要素が8個とすれば、
sum = (((((((a+b)+c)+d)+e)+f)+g)+h)
と順番に足していくことに相当します。この計算は括弧の深さが7ですから、7回のループが必要です。
これを並列でおこなうということは、同時にいくつかの足し算を行うということですから
sum = ( ((a+b)+(c+d)) + ((e+f)+(g+h)) )
ということになります。同じ深さの括弧内の計算が並列にできるならば、深さは3ですから、これは3回の処理で実行できます。
これが同じ結果になるのは、結合法則が適用できるからです。
次元削減が並列化できる条件は、要素同士の演算が結合法則を満たすとき、ということができます。
演算における左右の関係を保存することはできますので、可換(a+b=b+a)である必要はありません。
2.とりあえず、動かしてみる
サンプルに入っているものは、単純に配列の合計値を計算するものです。
ドキュメントによれば、ただ足し算を(要素数-1)回行うなので、計算量はほとんど小さく、
bandwith-optimal(実行速度はメモリ転送速度に規定される、あるいは、メモリ転送速度レベルまで最適化可能)となっています。
ドキュメントでは、7段階のコーディングで最適化を行い、それぞれのアルゴリズムのボトルネックを示し、
最適化の方針を立てています。この最適化の方法についてはのちほど書きたいと思います。
とりあえず動かしてみよう。
私の環境におけるバンド幅はデバイス内で15.47GB/sです。
一方、reductionを実行してみると、Bandwithは16.645024GB/s・・・って、メモリより速い?
おそらく、sampleのBandwidthTestと転送のデータ量が違うからだと思いますが、ぎりぎりまでチューンされているのが分かります。
ソースをちょっと改変して、CPUに単純に足し算させると、実行時間は4.000834msでしたた。
一方のGPUによる実行では、0.251985msで、約15.88倍の高速化がされています。
3.Shmooをやってみる
このReductionは--shmooオプションをつけることによって、Shmoo
Plotを行うことが出来ます。
Shmooというのはお化けのキャラクターで、このキャラクターのように右肩上がりのプロットになることからのネーミングらしいです・・・
これは、あるパラメーターをいろいろと変えた場合のアウトプットをプロットしたもので、
今回の場合は、合計をとる配列の要素数をいろいろと変えた場合の実行時間をプロットするものになっています。
さて、Shmooを行おうとすると、途中でエラーが起きて止まってしまいます。
エラーメッセージは”Invalid Configuration Argument."で、カーネル関数(GPU計算のメイン部分)に渡す、
並列化に関するパラメーター(ブロック数、スレッド数など、詳細は後ほど書いていきたいと思う)がおかしいということです。
デバッガで確認してみると、最初とまるところは、benchmarkReduce内でカーネル関数を呼び出した後でしたので、
デバッガでこれを確認すると、要素数1、スレッド数1、ブロック数1ということでした。
最初、スレッドやブロックが1というのは許されないのかと思い、テストの要素数が256ぐらいからはじまるようにしたり、
いろいろ試してみるがうまくいきません。
そのうち、このとまる場所はCUDA_CHECK_ERRORという関数(マクロ?)のところなのですが、
これがcudaGetLastErrorという関数を用いていること、そして、これが「最後に起きたエラーを取得する」ものであることが分かりました。
そこで、ソースコードを見てみると、SHMOOに入る前に一通り最大要素数(デフォルトでは32M個)でreductionを実行しているのですが、
ここではまったくエラーチェックを行っていません。
ということは、エラーが発生した場所は直近の関数ではなく、それ以前ということが考えられ、
最大要素数の場合、ブロック数が限界値である65536を超えてしまうことは想像に難くありません。
そこで、ソースコードに若干の変更を加えてみました。赤字が変更点です。
cudaError_t err;
for (int kernel = 0; kernel < 7; kernel++)
{
printf("\n");
printf("%d", kernel);
for (int i = minN; i <= maxN; i *= 2)
{
cutResetTimer(timer);
int numBlocks = 0;
int numThreads = 0;
getNumBlocksAndThreads(kernel, i, maxBlocks, maxThreads, numBlocks, numThreads);
err = cudaGetLastError();
benchmarkReduce(i, numThreads, numBlocks, maxThreads, maxBlocks, kernel,
testIterations, false, 1, timer, h_odata, d_idata, d_odata);
float reduceTime = cutGetAverageTimerValue(timer);
err = cudaGetLastError();
if( err == cudaSuccess)
{
printf(", %f", reduceTime);
}
else
{
printf(", ERROR");
}
}
}
ベンチマーク実行前に、エラーを取り出すことでリセットし、実行後にエラーが起きていたら、時間でなく”ERROR"と表示します。
またbenchmarakReduceの中でのCUDA_CHECK_ERRORの部分はコメントアウトし、エラーで動作が止まらないように修正しまし
た。(ソース省略)
それによって、正しいSHMOOプロットが得られた。
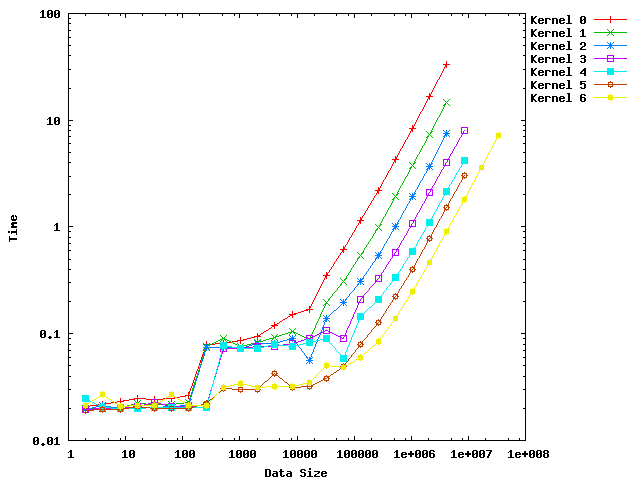
以下に、gnuplotを用いて出したプロットを表示します。
データ個数が2倍ずつになっているので、両対数グラフにしました。
最後は32M個ですが、ここにはKernel6のみが対応可能で、Kernel0-2は4M個まで、
Kernel3-5は8M個までで、それを超えるとブロック数が最大に到達するためにエラーになります。
要素数が128個以下の場合は、1ブロックで対応可能で、Kernelの差はあまりありませんが、
ブロックをまたぐものについては、Kernel最適化の影響をみることができます。
Kernel0-2については128と256で大きな差ができ、Kernel4-7では256と512の間に大きな差ができます。
また16K個まではほぼ横ばいのグラフが、32K個を超えると要素数に比例して時間が増大している様子が分かります。
このあたりの考察については、次の節で行いたいと思います。
4.Reductionの最適化について
詳しくはSDKにPDF形式でポイントが解説してあります。
英語ですがそれほど難しくはないでしょう。
ワープや共有メモリのバンク衝突回避に関する知識があれば理解できると思います。
Kernel最適化の最初の部分はそこがポイントになっています。
・CUDAでは剰余計算は遅いので、なるべくビット演算で代替するようにコーディングする。
・ワープごとに並列実行されるので、ステップが進むごとに稼動するスレッドが減っていくような場合、
スレッド番号が連続になるように割り振る。
・共有メモリのバンク衝突が起こらないように、スレッド番号に対してメモリアドレスもリニアになるように共有メモリを割り振る。
・ループの展開(ifやforなどの分岐命令はGPUにとって一般的に高価である)
ここまでがKernel4(SDKのPDFではKernel5)までの最適化です。
これだけでも一般的な最適化の指針となるでしょう。
Kernel5では、C++と同等のtemplateを使って、あらかじめ起動されるスレッド数を与えておき、
必要な数だけ加算を実行するようにループを完全に排除しています。
最後のKernel6では、Brentの定理というものを使って、各コアにどれだけの計算を割り振るか決めています。
(以下、追加予定)
次の記事